
SuperGloo is an open source project for service mesh orchestration at scale. SuperGloo provides an opinionated abstraction layer that simplifies the installation, management, and operations of one or more service meshes like Istio, AWS App Mesh, Linkerd, and HashiCorp Consul deployed on-prem, in the cloud or any combination you need.
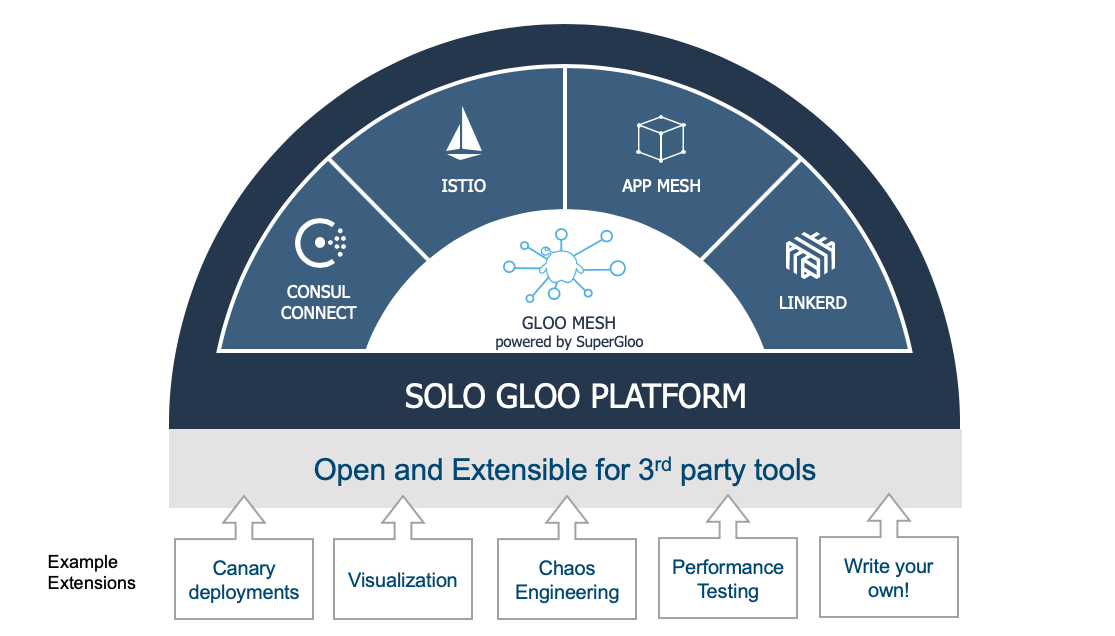
There are a growing number of articles on why SuperGloo, like Christian Posta’s “Solo.io Streamlines Service Mesh and Serverless Adoption for Enterprises in Google Cloud”. This article is going to focus on how SuperGloo can help software packages like Weaveworks Flagger work on multiple Services Meshes like Istio and AWS App Mesh that both support traffic shifting.
Flagger is a cool open source project that automates the promotion of Canary deployments of your Kubernetes services. You associate a Flagger Canary Kubernetes custom resource (CRD) with your deployment and Flagger follows your defined rules for helping roll out a new version. It detects when a new version of your service has deployed, instantiating your new version in parallel to your existing version, slowly shifting request traffic between the two versions, and using your defined Prometheus metric health checks to determine if Flagger should continue moving more traffic to the new version or roll back to the old version. Since a Canary CRD is a YAML file, this provides you a declarative way to ensure that all of your service upgrades follow your prescribed sophisticated rollout strategy and complements GitOps pipelines used in Weave Flux and JenkinsX.
More information on what Canary deployments and Traffic Shifting are is in the following posts. Gloo uses the same underlying data plane technology — Envoy — as Istio to provide traffic shifting capabilities used by Flagger and Knative. Gloo is an API/Function gateway and not a full Service Mesh, so Gloo can be used in use cases that do not require all of the power, and weight, of a full Service Mesh implementation.
- Canary Deployments with Gloo Function Gateway using Weighted Destinations
- Automating your Services with Knative and Solo.io Gloo
- Jenkins X Serverless Apps
This article quickly runs through setting up the Flagger podinfo example application on SuperGloo with Istio so you all can see what’s involved and try yourselves if you like.
Install Kubernetes and Helm
The first step on our journey is to get a basic local Kubernetes cluster running. My friend Christian Hernandez clued me in on kind (Kubernetes IN Docker) from the Kubernetes sig-testing team. It’s a fast, lightweight way to spin up/down a local cluster assuming you have a locally running copy of Docker, e.g., Docker Desktop. This example works equally well in minikube if you prefer. The following code does the basics you need for most Kubernetes clusters.
- Creates a
kindcluster with one control plane node and one worker node - Configures the
KUBECONFIGaskindcreates a separatekubeconfigfile for eachkindcluster - Installs Helm and Tiller with a service account for Tiller
Use SuperGloo to install and configure Istio
Here’s where the magic happens so let’s spend a little time teasing out all the things that are happening due to these few lines of code.
The first command supergloo init installs SuperGloo into your Kubernetes cluster that is equivalent to using Helm to install SuperGloo.
The second command kubectl --namespace supergloo-system rollout status deployment/supergloo --watch=true is a hack to wait till the SuperGloo deployment is fully deployed and running. It’s similar to using the --wait option on a Helm install.
The supergloo install istio ... command declares a custom resource and the SuperGloo controller installs and configures Istio as declared. In this case, we are installing Istio version 1.0.6 with Istio’s Prometheus installation and with Istio deploying sidecars in all pods within namespaces with the label istio-injection=enabled, i.e., Istio’s default behavior for auto-injecting sidecars. This imperative supergloo install istio command creates the following manifest that you could kubectl apply if you prefer. Refer to the full Install specification for more details.
Install Weaveworks Flagger
The following install Flagger and its dependent parts. The following is a quick summary of installing Flagger. More details at Flagger Doc Site.
- Add a reference to Flagger helm repo
- Wait for Tiller to be fully running. Only an issue for quick scripts that create Kubernetes clusters from scratch
- Create a cluster role binding that allows Flagger to modify SuperGloo/Istio resources
- Install core Flagger referencing Istio’s provided Prometheus and telling Flagger that SuperGloo is the mesh controller
- Install Flagger’s Grafana dashboards which are not used as part of this demo
- Install Flagger’s LoadTester which can help generate test traffic during a Canary deployment if there is not enough user traffic
Install Weaveworks Flagger example application
The example application podinfo is a simple golang web application. It is instrumented with Prometheus so we can tell if it’s performing well (or not) that helps with our Canary deployment to validate that the new version is handling incoming traffic. The example application also has hooks to allow you to generate faults if you want to explicitly fail a deployment to see how the Flagger Canary handles that situation. Full details on the options around the Flagger example application are here. The following is the summary of installation steps.
- Install a
testnamespace, the example Kubernetes Deployment manifest and an (optional) horizontal pod autoscaler - Deploy the Canary policy for the example application. More details on that in a moment
- Wait for the Canary controller to report that it’s fully ready, which means Istio and Flagger are fully deployed and running
The Canary manifest has a target reference that associates it with the podinfo deployment. The Canary analysis says that for every interval (1 minute) Flagger increment by stepWeight (10%) more request traffic to the new version up to maxWeight (50%) as long as the metrics stay within the defined healthy ranges. If more than threshold (5) health checks fail, then rollback to 100% of traffic to the old version and delete the new version deployment. There is also an optional section to allow the Flagger loadtester to generate additional traffic to help validate the new Canary version, i.e., hard to know if the new version works if it has not handled any requests.
Deploy a new image version and watch the canary deployment
First, we check on the currently deployed image version and print that out to help us verify if the test updates the service as we expect; should be quay.io/stefanprodan/podinfo:1.4.0. Then to help make the changes more visible, we trigger a background process to update the image version to quay.io/stefanprodan/podinfo:1.4.1 after a five-second delay. We then loop and print out the change events for podinfo to see the traffic weight changes until the Canary reports Success. You’d need to change this loop if you want to try introducing errors to see the Canary rollback. Lastly, we’ll print out the image version which should be quay.io/stefanprodan/podinfo:1.4.1 is everything succeeded.
Clean up Kubernetes
The final step is to clean up the Kubernetes cluster, which in our case means to delete the kind cluster by running kind delete cluster and unsetting the KUBECONFIG environment variable.
See Everything Together
Here’s an Asciinema screen recording of the whole example script running, and afterward you can see the whole script if you wanted to try yourself. The Asciinema recorder speeds up any long running commands, that is, if a command takes more than two seconds to execute the playback delays up to two seconds. This speedup reduces the run time from 15+ minutes to around two minutes.

Summary
Hopefully, this example gave you a taste of how SuperGloo supports a Canary deployment engine like Flagger. Before SuperGloo you’d either need to learn how to install all of Istio yourself or be constrained to using a managed Istio or App Mesh installation from GKE or AWS respectively. Those are good managed offerings, but they do limit your choices to the versions and configurations they currently support.
SuperGloo provides a great abstraction and management layer to help extensions leverage one or more Service Meshes without needing to get deep into the weeds of the huge API surface area of any one of the meshes like Istio or App Mesh. SuperGloo makes it easy for applications to use just what they need of the underlying meshes. That helps with adoption on Service Meshes based on the feedback I’ve heard, that is, many are currently experimenting with Istio or App Mesh or Linkerd for just on capability, typically traffic shifting or mutual TLS, and they’re finding it difficult to manage and configure the whole mesh even though they aren’t using those other capabilities. SuperGloo to the rescue to help make it easier to use just the parts of Service Meshes that add value today, and allow you to add more as you need it including mixing and matching multiple service meshes easily to get the biggest return on your investment.
I strongly encourage you to learn more yourself as its fun to learn new technology, especially tech that helps you solve complex challenges and accelerates your ability to deploy larger and more sophisticated systems.
- SuperGloo
- Flagger
- Istio
- Service Mesh Hub



























%20a%20Bad%20Idea.png)











%20For%20More%20Dependable%20Humans.png)










